

En la era contemporánea de la inteligencia artificial, la capacidad de interactuar de manera efectiva con información se ha vuelto crucial. La generación aumentada por recuperación (RAG) es un enfoque innovador que optimiza las salidas de los modelos de lenguaje de gran tamaño (LLM) al referirse a bases de conocimiento autorizadas antes de generar respuestas.
Este método no solo mejora la precisión y relevancia de las respuestas en base a un conocimiento o información en específico, sino que también permite a las organizaciones controlar la información que se proporciona, asegurando que sea actual y confiable.
En este blog, exploraremos el funcionamiento de una RAG básica que utiliza embeddings para almacenar y recuperar texto. Comenzaremos con una introducción a los conceptos fundamentales, como los embeddings y los LLM, seguidos de un ejercicio práctico en Python que desglosa la arquitectura de la RAG y analiza el código en detalle.
Acompáñame en este recorrido y crea tu propio agente de chat el cual te responderá consultas y preguntas a partir de los documentos que tú le proporciones.
Conceptos Clave
Para comprender cómo funciona la generación aumentada por recuperación (RAG), es fundamental familiarizarse con algunos conceptos clave que son la base de esta tecnología.
Embeddings
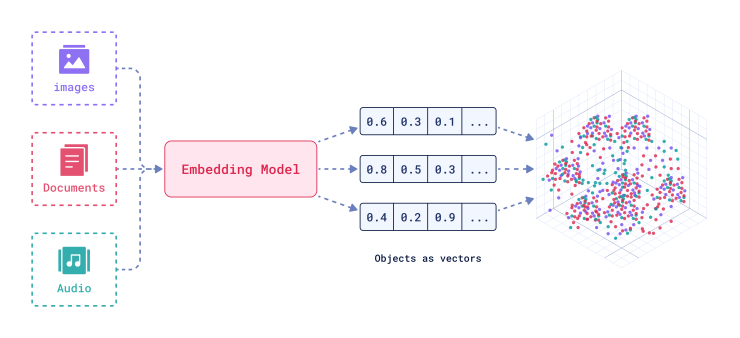
Los embeddings son representaciones numéricas de datos que permiten que un modelo entienda y procese información de manera más eficiente.
En el contexto de la RAG, los embeddings convierten el texto en vectores de alta dimensión que capturan las relaciones semánticas entre palabras y frases.
Esta representación facilita la búsqueda y recuperación de información relevante, ya que los embeddings pueden ser comparados matemáticamente para determinar similitudes. Aquí puedes revisar una explicación más amplia de este tema -> What are Vector Embeddings?
Modelos de Lenguaje Grande (LLM)
Los modelos de lenguaje de gran tamaño son sistemas de inteligencia artificial entrenados con grandes volúmenes de datos para generar texto coherente y contextualmente relevante.
Estos modelos utilizan miles de millones de parámetros para aprender patrones en el lenguaje, lo que les permite llevar a cabo tareas como responder preguntas, traducir idiomas y completar frases.
Sin embargo, los LLM pueden presentar desafíos, como generar información desactualizada o incorrecta, lo que hace que la integración de RAG sea valiosa para mejorar su precisión. Ejemplos de modelos LLM son ChatGPT, Claude, Gemini y LLaMA.
Generación Aumentada por Recuperación (RAG)
RAG combina la potencia de los LLM con la capacidad de recuperación de información de bases de conocimiento externas. A través de este enfoque, un LLM puede extraer datos de fuentes autorizadas antes de generar una respuesta, asegurando que la información proporcionada sea relevante y actualizada.
Esto permite que los LLM no solo se basen en sus datos de entrenamiento estáticos, sino que accedan a información dinámica, lo que mejora la confianza y la utilidad de las respuestas generadas.
Arquitectura RAG
Para este caso práctico he descargado algunos pdf generados a partir de varias páginas de wikipedia que contienen información de deportes, tecnología, medicina, etc. Este dataset lo puedes encontrar en Kaggle -> PDFsTemasVarios
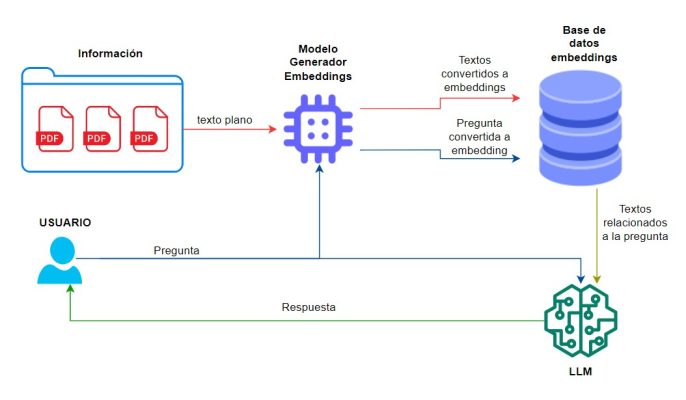
La arquitectura de la RAG comienza con la recopilación de documentos PDF desde una ruta específica. Este proceso implica extraer el texto contenido en los PDFs y transformarlo en embeddings mediante el modelo hiiamsid/sentence_similarity_spanish_es de Hugging Face. Estos embeddings capturan el significado semántico del texto y nos facilitaran la posterior búsqueda y comparación con la pregunta.
Una vez generados, estos embeddings se almacenan en ChromaDB, una base de datos diseñada para gestionar datos vectoriales. Esto permite una recuperación eficiente de la información relevante.
Cuando un usuario realiza una consulta, esta también se convierte en un embedding. A continuación, se lleva a cabo una búsqueda en ChromaDB para encontrar los embeddings más similares a la consulta del usuario. Esta búsqueda permite recuperar el contexto relevante que se utilizará para responder a la pregunta.
Con el contexto identificado, se pasa tanto este contexto como la pregunta al modelo de lenguaje. El LLM, genera una respuesta informada y coherente basada únicamente en el contexto proporcionado, asegurando que la información sea relevante y precisa.
Implementación en código
%%capture
!pip install --upgrade pip # Actualiza pip a la última versión
!pip install pymupdf # Instala pymupdf, una biblioteca para manejar archivos PDF
!pip install chromadb # Instala chromadb, una base de datos para almacenar embeddings
!pip install sentence_transformers # Instala sentence_transformers, una biblioteca para trabajar con modelos de embeddings
!pip install openai # Instala openai, la biblioteca para interactuar con la API de OpenAIPreparamos el ambiente de desarrollo instalando todas las librerías necesarias.
import os # Para interactuar con el sistema operativo
import io # Para operaciones de entrada y salida
import re # Para trabajar con expresiones regulares
from getpass import getpass # Para pedir contraseñas de forma segura
import fitz # Para manipular archivos PDF (PyMuPDF)
import chromadb # Para manejar la base de datos de embeddings
import openai # Para interactuar con la API de OpenAI
import matplotlib.pyplot as plt # Para crear visualizaciones y gráficos
from PIL import Image # Para trabajar con imágenes
from sentence_transformers import SentenceTransformer # Para generar embeddings de oraciones
from transformers import pipeline # Para trabajar con modelos de NLP de Hugging FaceEstas importaciones establecen todas las bibliotecas y módulos necesarios para implementar y ejecutar la arquitectura RAG.
# Solicita la clave de API de OpenAI de forma segura
openai.api_key = getpass("Ingrese la clave de OpenAI")"getpass("Ingrese la clave de OpenAI")": Usa la función getpass para solicitar al usuario que ingrese la clave de API de OpenAI. Esta función no muestra la entrada en la pantalla, proporcionando una forma segura de introducir contraseñas o claves de API.
"openai.api_key": Asigna la clave ingresada al atributo api_key de openai, permitiendo la autenticación y el acceso a los servicios de OpenAI.
En este caso hemos usado GPT 3.5, pero puedes optar por otros modelos. Te invito a revisar algunos de los LLM disponibles en el siguiente link -> Modelos LLM
model = SentenceTransformer("hiiamsid/sentence_similarity_spanish_es") # Carga el modelo de SentenceTransformer para generar embeddings en español"hiiamsid/sentence_similarity_spanish_es": Especifica el nombre del modelo preentrenado que se va a cargar. En este caso, es un modelo open source para calcular la similitud de oraciones en español.
"model": Almacena el modelo cargado, que se utilizará para convertir textos en embeddings que representen su contenido semántico.
def extractInformation(path: str):
chunk_size = 600 # Tamaño del fragmento de texto
overlap = 100 # Superposición entre fragmentos
listChunks = [] # Inicializa una lista para almacenar los fragmentos de información extraídos
documents = os.listdir(path) # Obtiene la lista de documentos en la ruta especificada
for document in documents:
print("processing file: {}".format(document))
allPath = path + document
extention = os.path.splitext(allPath)[1].lower()[1:] # Obtiene la extensión del archivo
if extention == 'pdf': # Si el documento es un archivo PDF
pdf_document = fitz.open(allPath) # Abre el archivo PDF
for page_num in range(pdf_document.page_count):
page = pdf_document.load_page(page_num) # Carga una página del PDF
textPage = page.get_text("text") # Extrae el texto de la página
cleaned_text = re.sub(r'(\s|\n|\r){2,}', ' ', textPage) # Elimina espacios y saltos de línea extra
for i in range(0, len(cleaned_text), chunk_size - overlap):
chunk = cleaned_text[i:i + chunk_size] # Divide el texto en fragmentos
listChunks.append([allPath, document, page_num + 1, chunk]) # Agrega el fragmento a la lista
if len(chunk) < chunk_size:
break
return listChunks # Devuelve la lista de fragmentos extraídos
def saveDocuments(documents: list, collection, model):
print("Uploading information to the model.")
chunks = [i[3] for i in documents]
embeddings = model.encode(chunks) # Genera embeddings para los documentos
embeddings = embeddings.tolist()
collection.add(
documents=chunks,
embeddings=embeddings,
metadatas=[{"path": documento[0], "nombre": documento[1], "pagina": documento[2]} for documento in documents],
ids=["id{}".format(i) for i in range(len(chunks))]
)#Agrega los embeddings a la base de datos
def mostrarPagina(pdf_path, page_number):
document = fitz.open(pdf_path) # Abre el archivo PDF
page = document.load_page(page_number - 1) # Carga la página especificada (las páginas comienzan en 0)
pix = page.get_pixmap() # Obtiene un objeto de mapa de bits de la página
image = Image.open(io.BytesIO(pix.tobytes())) # Convierte la imagen a un formato que matplotlib pueda mostrar
plt.figure(figsize=(8, 10))
plt.imshow(image)
plt.axis('off')
plt.show() # Muestra la imagen de la página
# Define una función para interactuar con el modelo GPT-3 de OpenAI
def answerOpenAI(context: str, question: str):
result = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Eres un asistente al cuál se le va hacer una pregunta. "+
"Tú no tienes ningún tipo de conocimiento ni información alguna. "+
"Tienes que responderme la pregunta solo con la información que se te va a dar en el contexto. "+
"Si la información necesaria no está en el contexto no vas a poder responder la pregunta."},
{"role": "user", "content": "Este es el contexto '{0}' y esta es la pregunta '{1}'".format(context[:3500], question)}
],
max_tokens=100,
temperature=0
)
return result.choices[0].message.content # Devuelve la respuesta generada por GPT-3"extractInformation(path: str)": Extrae y divide el texto de archivos PDF en fragmentos.
"saveDocuments(documents: list, collection, model)": Guarda los fragmentos y sus embeddings en una colección de ChromaDB.
"mostrarPagina(pdf_path, page_number)": Muestra una página específica de un archivo PDF usando matplotlib.
"answerOpenAI(context: str, question: str)": Interactúa con el modelo GPT-3 de OpenAI para generar respuestas basadas en un contexto proporcionado.
path = '/kaggle/input/pdfstemasvarios/' # Ruta a los documentos PDF
chunks = extractInformation(path) # Extrae información de los documentos PDF
client = chromadb.Client() # Crea un cliente para interactuar con ChromaDB
collection = client.get_or_create_collection(name="chunks", metadata={"hnsw:space": "cosine"}) # Verifica si la colección "chunks" existe, sino la crea.
#Si se desea mantener la información de chunks cargados anteriormente se puede eliminar el código antes de usar la función saveDocuments
if collection: # Si la colección existe
client.delete_collection(name="chunks") # Elimina la colección existente para evitar duplicados
# Crea una nueva colección llamada "chunks" con la configuración de búsqueda tipo "coseno" para tener un mejor resultado para este caso.
collection = client.create_collection(name="chunks", metadata={"hnsw:space": "cosine"})
# Guarda los fragmentos y sus embeddings en la colección
saveDocuments(chunks, collection, model) processing file: Nutricin.pdf
processing file: Derecho.pdf
processing file: Medicina.pdf
processing file: Religin.pdf
processing file: Ejercicio_fsico.pdf
processing file: Biotecnologa.pdf
processing file: Inteligencia_artificial.pdf
processing file: Tecnologa.pdf
processing file: Ftbol.pdf
processing file: Exploracin_espacial.pdf
processing file: Arte.pdf
processing file: Cine.pdf
processing file: Medio_ambiente_natural.pdf
processing file: Energa_renovable.pdf
processing file: Economa.pdf
processing file: Zoologa.pdf
processing file: Poltica.pdf
processing file: Enfermedad.pdf
processing file: Educacin.pdf
processing file: Animalia.pdf
processing file: Ingeniera_de_software.pdf
processing file: Videojuego.pdf
processing file: Banco.pdf
processing file: Historia.pdf
Uploading information to the model.
El código se conecta a ChromaDB y gestiona una colección llamada «chunks» utilizando un espacio de búsqueda basado en la distancia coseno. Esta métrica permite evaluar la similitud entre los embeddings de los fragmentos de texto y las consultas del usuario, facilitando la recuperación de la información más relevante. Al utilizar la distancia coseno, se optimiza la precisión en la búsqueda de contextos relacionados con las preguntas planteadas.
while True: # Inicia un bucle que continuará hasta que se interrumpa
question = input("Realiza una pregunta: ") # Solicita al usuario que ingrese una pregunta
if question.lower() == 'salir': # Si la pregunta es 'salir', termina el bucle
break
# Realiza una consulta en la colección utilizando el embedding de la pregunta
documentos = collection.query(
query_embeddings=model.encode([question]).tolist(), # Convierte la pregunta en un embedding
include=["documents", "metadatas"], # Incluye documentos y metadatos en la respuesta
n_results=1 # Limita el resultado a un único documento más relevante
)
print("Puedes revisar los siguientes documentos:\n") # Mensaje para indicar que se mostrarán los documentos
for indice, metadata in enumerate(documentos["metadatas"][0]): # Itera sobre los metadatos de los documentos
print("Archivo: " + metadata['nombre'] + "\n") # Muestra el nombre del archivo
print("Página: " + str(metadata['pagina']) + "\n") # Muestra el número de página
# Genera una respuesta utilizando el contexto recuperado y la pregunta
print("Respuesta: " + answerOpenAI(documentos['documents'][0][indice], question) + "\n")
print("Contexto: \"" + documentos['documents'][0][indice] + "\"\n") # Muestra el contexto del documento
mostrarPagina(metadata['path'], metadata['pagina']) # Muestra la página del PDF correspondienteEl código permite al usuario hacer preguntas en un bucle continuo. Al ingresar una pregunta, se convierte en un embedding y se realiza una consulta en la colección de ChromaDB para encontrar el documento más relevante. Se muestra el nombre del archivo, el número de página y se genera una respuesta utilizando el contexto recuperado. Además, se presenta visualmente la página del PDF correspondiente a la consulta. El bucle continúa hasta que el usuario escribe ‘salir’.
Resultado
A continuación presentaré algunos ejemplos al realizar consultas a este agente:
- Ejemplo 1: ¿Desde qué época se ha practicado la medicina?
Realiza una pregunta: ¿Desde qué época se ha practicado la medicina?
Loading widget...
Puedes revisar los siguientes documentos:
Archivo: Medicina.pdf
Página: 2
Respuesta: La medicina se ha practicado desde la prehistoria.
Contexto: "istoria de la medicina es la rama de la historia dedicada al
estudio de los conocimientos y prácticas médicas a lo largo del
tiempo. También es una parte de cultura.
Desde sus antiguos orígenes, el ser humano ha tratado de explicarse
la realidad y los acontecimientos trascendentales que en ella tienen
lugar, como la vida, la muerte o la enfermedad. La medicina tuvo
sus comienzos en la prehistoria, la cual también tiene su propio
campo de estudio conocido como antropología médica. Se
utilizaban plantas, minerales y partes de animales. En la mayoría de
las veces estas sustancias eran utilizadas "

- Ejemplo 2: ¿En qué año se fundó la Confederación Sudamericana de Fútbol?
Realiza una pregunta: ¿En qué año se fundó la Confederación Sudamericana de Fútbol?
Loading widget...
Puedes revisar los siguientes documentos:
Archivo: Ftbol.pdf
Página: 6
Respuesta: La Confederación Sudamericana de Fútbol (Conmebol) se fundó en 1916.
Contexto: "etición de selecciones. La medalla de oro quedó en manos de la selección de fútbol del
Reino Unido.
En 1916 se fundó la Confederación Sudamericana de Fútbol (Conmebol), que ese mismo año
organizó la primera edición del Campeonato Sudamericano de Fútbol, actual Copa América —
dicho torneo se mantiene como el más antiguo de la historia del fútbol a nivel de selecciones,
de los que todavía existen—.39 En esa primera edición participaron Argentina, Brasil, Chile y
Uruguay, resultando campeón este último.
La Primera Guerra Mundial hizo retroceder el desarrollo del fútbol, pero las ediciones de 19"

- Ejemplo 3: ¿Por qué es importante la educación?
Realiza una pregunta: ¿Por qué es importante la educación?
Loading widget...
Puedes revisar los siguientes documentos:
Archivo: Educacin.pdf
Página: 11
Respuesta: La educación es importante porque permite la accesibilidad de toda la población a la educación y genera niveles de instrucción deseables para la obtención de una ventaja competitiva.
Contexto: "ación escolarizada de diversos niveles académicos siendo preeminente
la realización de los niveles que la norma jurídica considere obligatorios. El término se aplica generalmente a la
educación formal, la educación preescolar, primaria y secundaria.44 También se aplica a la educación post-
secundaria, educación superior, o las universidades, colegios y escuelas técnicas que reciben ayudas públicas.
El objetivo de la educación pública es la accesibilidad de toda la población a la educación y generar niveles de
instrucción deseables para la obtención de una ventaja competitiva. Regularmente la"

- Ejemplo 4: ¿Quién es Anderson Meza?
Realiza una pregunta: ¿Quién es Anderson Meza?
Loading widget...
Puedes revisar los siguientes documentos:
Archivo: Ingeniera_de_software.pdf
Página: 21
Respuesta: Lo siento, no tengo información suficiente para responder a esa pregunta.
Contexto: "~molguin/as/RUP.htm) el 29 de
marzo de 2014 en Wayback Machine.,
artículo en el sitio web Yaqui.
38. Pressman, Roger S.: Ingeniería del
software: un enfoque práctico. Sexta
edición, pág. 67-72.
39. Bernd Bruegge & Allen H.Dutoit. Object-
Oriented Software Engineering, Prentice
Hall, Pag. 11.
40. Pressman, 2002, p. 39
41. «O*NET Code Connector - Software
Developers, Systems Software - 15-
1133.00» (https://www.onetcodeconnector.o
rg/ccreport/15-1133.00).
"

En este último ejemplo, dado que en ningún archivo está la información que dé respuesta a la consulta, el agente no puede responder con seguridad. En cuanto al contexto, nos trajo parte de la bibliografía, la cual consideró como el contenido más relacionado a la pregunta.
Conclusión
Hemos explorado el funcionamiento básico de una arquitectura de Recuperación Aumentada por Generación (RAG). Con esto creo que es importante destacar algunos puntos:
- Destaco la importancia de la limpieza del texto previo a la carga en la base de embeddings. Este proceso es crucial, ya que la calidad del texto depende en gran medida de su origen y estructura, lo que afecta la efectividad de las consultas.
- Si bien la la transformación de texto a embeddings la hicimos con un modelo open source, también se lo puede hacer con proveedores como OpenAI. Estos pueden dar mejores resultados. Sin embargo, tiene un costo que habría que considerar dependiendo del proyecto.
- El uso de un prompt adecuado evita alucinaciones, permitiendo que el modelo responda con precisión basado únicamente en el contexto proporcionado.
- En el ejemplo se pide que extraiga el texto con mayor relación a la pregunta. Sin embargo, se puede modificar el número de resultados en la consulta, y con esto obtener un contexto más amplio, lo cual puede enriquecer las respuestas generadas.
- La elección de un tamaño de chunk de 600 caracteres se adaptó a este ejemplo, pero es importante tener en cuenta que este valor puede variar según el tipo de proyecto. Un tamaño demasiado pequeño puede resultar en la pérdida de información crucial, mientras que uno demasiado grande puede generar embeddings genéricos y poco útiles.
Resumen
Este ejemplo básico de RAG es solo el comienzo. En el contexto actual existen soluciones más complejas y avanzadas. De hecho existen frameworks que nos ayudan a orquestar todo el trabajo con estos modelos. Mi favorito es LangChain, que integra múltiples herramientas para crear agentes de chat más sofisticados. Próximamente estaré compartiendo más contenido sobre el uso de LangChain en futuros blogs, donde profundizaremos en su capacidad para mejorar la interacción con sistemas de inteligencia artificial.
Espero que este blog te haya permitido tener una mejor comprensión sobre la Recuperación Aumentada por Generación (RAG) y su aplicación en el manejo de documentos. La inteligencia artificial está en constante evolución, y explorar estas tecnologías puede abrir nuevas oportunidades para mejorar procesos y soluciones. Si quieres aprender más acerca de IA puedes revisar mis otros blogs -> Blogs
Adicional puedes revisar un poco más de información acerca de las RAGs en el siguiente link -> ¿Qué es la RAG (generación aumentada por recuperación)?.
Finalmente, te comparto el notebook con el código para que tú puedas crear tu propia RAG colocando los documentos que desees. Simplemente adapta la ruta de los archivos PDF y ajusta los parámetros según tus necesidades -> Plantilla RAG